

 Время чтения 17 минут | прочитали: 770
Время чтения 17 минут | прочитали: 770Дубли на сайте – это страницы с идентичным либо схожим контентом. Ситуация возникает из-за особенностей работы CMS, изменения структуры ресурса, ошибок в директивах файла robots.txt, неправильном указании 301-ых редиректов, некорректных настройках, при неверной кластеризации, автогенерации.
Как дубли влияют на позиции сайта
Дубли страниц отрицательно сказываются на SEO-продвижении и часто становятся препятствием для выхода сайта, даже с грамотно проработанным семантическим ядром и наличием релевантных запросов, в ТОП поисковой выдачи.
Опасность дубликатов заключается в следующем:
- Уменьшение процента уникальности текстов. При наличии дублей копия окажется неуникальной по отношению к основной странице. Как итог – общая уникальность сайта снизится.
- Разделение «веса». Стандартно поисковые системы по одному запросу показывают только единственную страницу сайта. Наличие нескольких однотипных документов уменьшает значимость каждого URL.
- Наложение санкций со стороны ПС. Дубли – не причина к пессимизации ресурса. Однако если поисковые алгоритмы посчитают, что копии создаются намеренно, чтобы манипулировать выдачей, будут предприняты соответствующие меры, которые приведут к снижению позиций сайта.
- «Неэффективная» рекламная кампания. ПС могут неправильно идентифицировать релевантную страницу при доступности контента по двум URL. Например, http://site.ru/avto и http://site.ru/catalog/avto. В ситуации, когда владелец сайта вложит средства в продвижение первой страницы, и на ресурс начнут ссылаться тематические площадки, а контент займет первые позиции в ТОП-10, в определенный момент робот может исключить URL из индекса, поскольку посчитает основным второй адрес, который ранжируется хуже и привлекает меньше целевого трафика.
- Увеличение времени на индексацию. На сканирование каждого ресурса, т. е. переобход сайта, у поисковых алгоритмов существует краулинговый бюджет – максимальное количество страниц, которое посещается за определенный период. Если на площадке присутствует много дубликатов, робот может не добраться до основного контента, из-за чего индексация затянется.
Дубли страниц усложняют и задачи вебмастера. Например, если долго откладывать работу над устранением копий, из-за большого количества лишних адресов повышается риск ошибок при обработке отчетов, выявлении и систематизации причин, внесении корректировок.
Виды дублей
Принято выделять явные и неявные дубли страниц.
Явные
Под явными дублями подразумеваются ситуации, когда одна и та же страница с идентичным контентом доступна по двум и более адресам. Причем варианты URL могут быть различными.
URL с WWW и без
Например, страница может открываться по адресам: http://www.site.ru/avto/ и http://site.ru/avto/. Чтобы исправить ситуацию, нужно указать на главное зеркало сайта, для чего необходимо:
- Перейти в панель «Яндекс.Вебмастер» и добавить 2 версии площадки – с WWW и без.
- Выбрать сайт, с которого планируется перенаправлять (стандартно – на URL без WWW).
- Зайти в раздел «Индексирование/Переезд сайта» и снять отметку с пункта «Добавить WWW».
- Сохранить изменения.
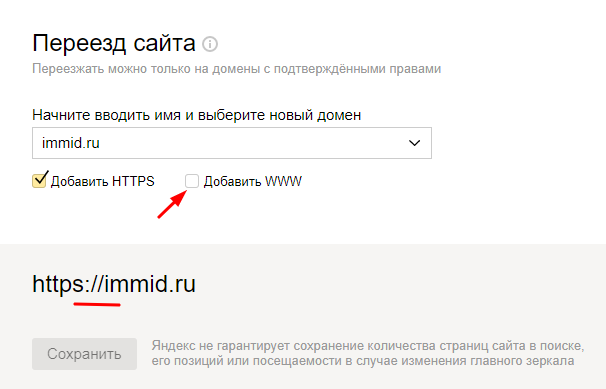
Яндекс в течение двух недель «склеит» зеркала и выполнит переиндексацию страниц. В результате в поисковой выдаче отобразятся только URL-адреса без WWW.
Раньше для указания на главное зеркало в robots.txt прописывалась директива Host. Сейчас правило не поддерживается, однако многие вебмастера продолжают прописывать правило, что необязательно, поскольку достаточно настроить склейку в «Яндекс.Вебмастере».
Что касается поисковой системы Google, указать на главное зеркало можно несколькими вариантами:
- Настроить 301-ый редирект на предпочтительную версию сайта. Если вебмастер не указал перенаправление после открытия ресурса для индексации, рекомендуется проанализировать, каких страниц больше в поисковой выдаче Google и настраивать переадресацию на нужный URL.
- Настроить канонические страницы (с учетом рекомендациям Google), т. е. подразумевается добавление в код тега с атрибутом rel="canonical" либо включение HTTP-заголовка rel=canonical.
Раньше, чтобы обозначить главное зеркало, достаточно было подтверждения прав в Search Console на обе версии (с WWW и без) и указания Google предпочтительного адреса в разделе «Настройки сайта». Сейчас схема не работает.
Адреса с GET-параметрами
Символы, которые находятся в URL после ?, называются GET-параметрами, которые разделяются между собой знаком &. Причем каждый новый адрес считается дубликатом главной страницы. Например, если в качестве последней взять https://site.ru/avto, то характерной может оказаться следующая ситуация:
- URL с идентификатором сессии: https://site.ru/avto/?sid=x12k22p75;
- URL с UTM-метками: https://site.ru/avto/?utm_source=google&utm_medium=cpc&utm_campaign=poisk;
- URL с тегом Google Ads: https://site.ru/avto/?gclid=Kamp1.
Для избавления от дублей можно применить несколько способов:
- Указать запрет на индексацию страниц с GET-параметрами в файле robots.txt. Например, для всех роботов код следующий:
User-agent: *
Disallow: /*?utm_source=
Disallow: /*&utm_medium=
Disallow: /*&utm_campaign=
Disallow: /*?sid=
Disallow: /*?gclid= - Задействовать директиву Clean-param для файла robots.txt, которую поддерживает Yandex. Правило запрещает поисковым алгоритмам обход адресов с GET-параметрами. Преимущество директивы – если исходная страница не проиндексирована, робот узнает о ней и включит в индекс. При закрытии от индексации адресов с GET-параметрами посредством Disallow алгоритмы ПС даже не станут обращаться к URL. В результате основная страница останется не проиндексированной. Более детально ознакомиться с директивой можно в Справке Яндекса.
Стоит учитывать, что Clean-param применим только в Яндексе, т. е. поисковая система Google не понимает директиву. Итог – задействовать в Гугле Disallow.
Пример кода:
User-agent: Yandex
Clean-param: utm_source&utm_medium&utm_campaign&sid&gclid
User-agent: Googlebot
Disallow: /*?utm_source=
Disallow: /*&utm_medium=
Disallow: /*&utm_campaign=
Disallow: /*?sid=
Disallow: /*?gclid=
URL со слешем в конце и без
Страница может показываться по адресам: http://site.ru/avto/ и http://site.ru/avto. Решение – настройка ответа сервера «HTTP 301 Moved Permanently» (301-й редирект), для чего потребуется:
- Найти и открыть .htaccess, который находится в корневой папке сайта. При отсутствии файла нужно создать документ в формате TXT с соответствующим названием.
- Прописать в документе указания для редиректа с URL со слешем на адрес без:
RewriteCond %{REQUEST_FILENAME} !-d
RewriteCond %{REQUEST_URI} ^(.+)/$
RewriteRule ^(.+)/$ /$1 [R=301,L]
При создании файла с нуля редиректы помещаются между строк:
<IfModule mod_rewrite.c>
…
</IfModule>
Рассмотренный способ с настройкой 301-редиректа посредством файла .htaccess применим только для ресурсов на Apache. Для Nginx и других серверов схема выглядит иначе. Причем, при выборе предпочтительного отображения URL, т. е. со слешем либо без, разницы никакой нет и нужно ориентироваться по ситуации. Например, с учетом количества проиндексированных страниц.
Адреса с HTTP и HTTPS
Ресурсы с SSL-сертификатами имеют преимущество в результатах поиска. Однако из-за ошибок при переходе сайта на HTTPS возникают дубли страниц. Например, https://site.ru/avto/ и http://site.ru/avto/.
Чтобы избавиться от копий, необходимо:
- Посмотреть корректность «склейки» зеркал в панели «Яндекс.Вебмастер». Процедура напоминает схему с WWW и без. Разница только в том, что в основном зеркале нужно отметить пункт «Добавить HTTPS».
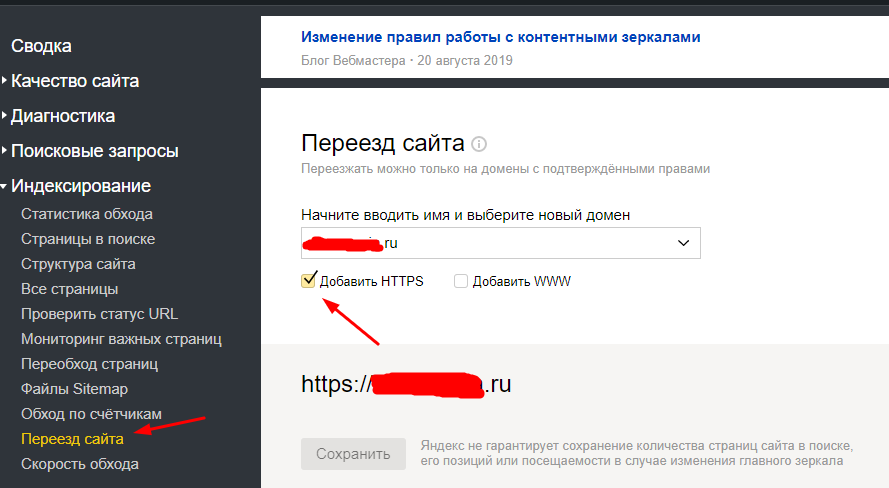
- Проверить настройки редиректов. Возможно, в коде присутствуют ошибки.
Часто проблема заключается не в наличии недочетов, а в том, что после настройки HTTPS поисковым системам необходимо время для удаления из индекса прежних адресов. Поэтому, прежде чем предпринимать какие-то действия, рекомендуется подождать несколько недель.
Версии для печати
Текст исходной страницы и версии для печати совпадает, т. е. адреса считаются дубликатами. Например, если в качестве первой взять https://site.ru/avto.html, второй вариант – https://site.ru/avto.html /?print=1 либо возможен и такой тип отображения URL: https://site.ru/avto.html/print.php?postid=1
Для избавления от дублей нужно закрыть поисковому роботу в файле robots.txt доступ к печатным версиям материалов. Если страницы выводятся посредством GET-параметра ?print, можно задействовать директивы Clean-param (для Яндекса) и Disallow (Google):
User-agent: Googlebot
Disallow: /*?print=
User-agent: Yandex
Clean-param: print
При варианте вывода на печать https://site.ru/avto.html/print.php?postid=1 можно указать директиву Disallow для обоих роботов:
User-agent: *
Disallow: /*print.php
Идентичный товар, доступный по различным адресам
Часто для сайтов, особенно интернет-магазинов с большим количеством продукции, характерна ситуация, когда один и тот же товар доступен для просмотра по разным URL-адресам. Например, если компания предлагает купить музыкальные диски, и пользователь может просмотреть и заказать продукты и со страницы https://site.ru/catalog/compact_disc, и https://site.ru/compact_disc. Чтобы избавиться от дублей, придется настроить rel="canonical" для тега <link>. Атрибут указывает на каноническую страницу, которая и попадет в индекс. Пример: Вебмастеру нужно указать поисковому роботу для индексации адрес https://site.ru/catalog/compact_disc, который считается каноническим, а https://site.ru/compact_disc - дублем. Для решения необходимо в раздел страницы-копии включить строку:<link rel="canonical" href=" https://site.ru/catalog/compact_disc" / >
Код означает, что с копии происходит ссылка на каноническую страницу, которая и попадет в индекс.
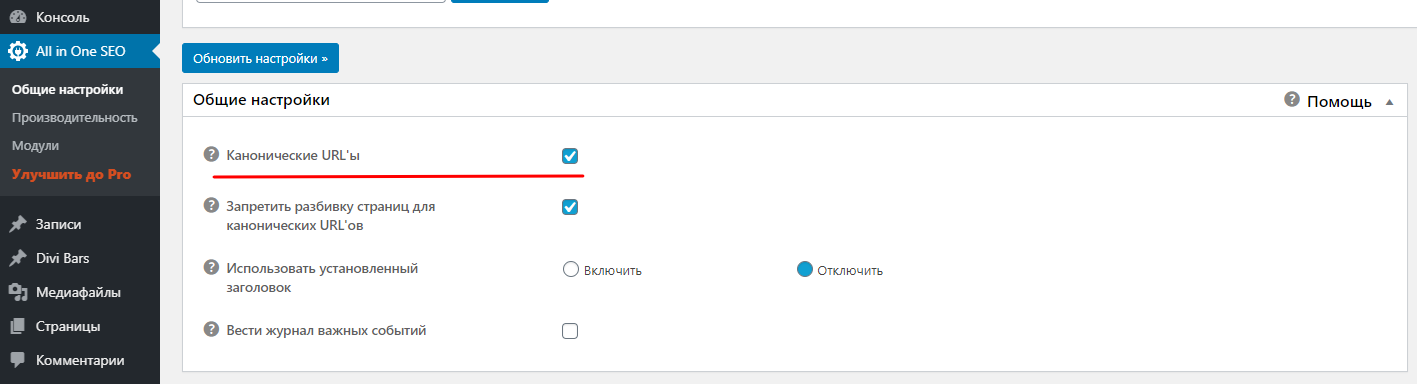
Настроить rel="canonical" можно средствами PHP, посредством встроенного функционала CMS либо плагинами. Если сайт разработан на платформе WordPress, достаточно установить All in One SEO Pack, позволяющий управлять каноническими адресами вручную и автоматически.
Неявные
Неявные дубли по разным URL-адресам показывают не идентичный, но похожий контент, который различается незначительно.
Страницы товаров с похожими описаниями
В интернет-магазинах товары часто различаются только по нескольким параметрам. Например, по материалу, размеру и другим характеристикам. Как результат – многочисленные карточки товаров показывают однотипный контент, а поисковые системы индексируют одну из них, которую считают наиболее релевантной, не уделяя особого внимания другим и относя к дублям.
Что делать:
- Уникализировать описания. Можно начать со значимых и приносящих наибольший доход товаров. Это позволит постепенно заполнить карточки уникальными текстами, а поисковые системы не будут воспринимать контент за копию.
- Объединить однотипные товары в единственной карточке, добавить селектор для выбора различающихся характеристик. Метод не только избавит от дублей страниц, но и упростит навигацию для клиентов.
Можно скрыть часть описания, которая повторяется в карточках, причем смысла для повышения уникальности контента нет. Например, указываются базовые характеристики, предоставленные производителем. Необходимый тег – noindex.
Пример:
<!--noindex-->повторяющийся контент<!--/noindex-->
Характеристики, которые различаются, закрывать не нужно, чтобы ПС понимали, что представлены различные товары. Однако такой способ действует не всегда и применяется чаще в качестве временного решения, поскольку тег noindex воспринимается только Яндексом.
Дубли древовидных комментариев (replytocom)
Ситуация характерна для ресурсов, разработанных на платформе WordPress. Например, когда посетитель сайта ответит на комментарий к прочитанной записи, CMS сгенерирует новый URL. И чем большее количество сообщений, тем выше процент дублирующихся адресов, которые стабильно индексируются поисковыми системами.
Для решения можно:
- Перейти в раздел «Настройки», после – «Обсуждение», и снять отметку напротив пункта «Разрешить древовидные (вложенные) комментарии глубиной … уровней». Останется только сохранить изменения.
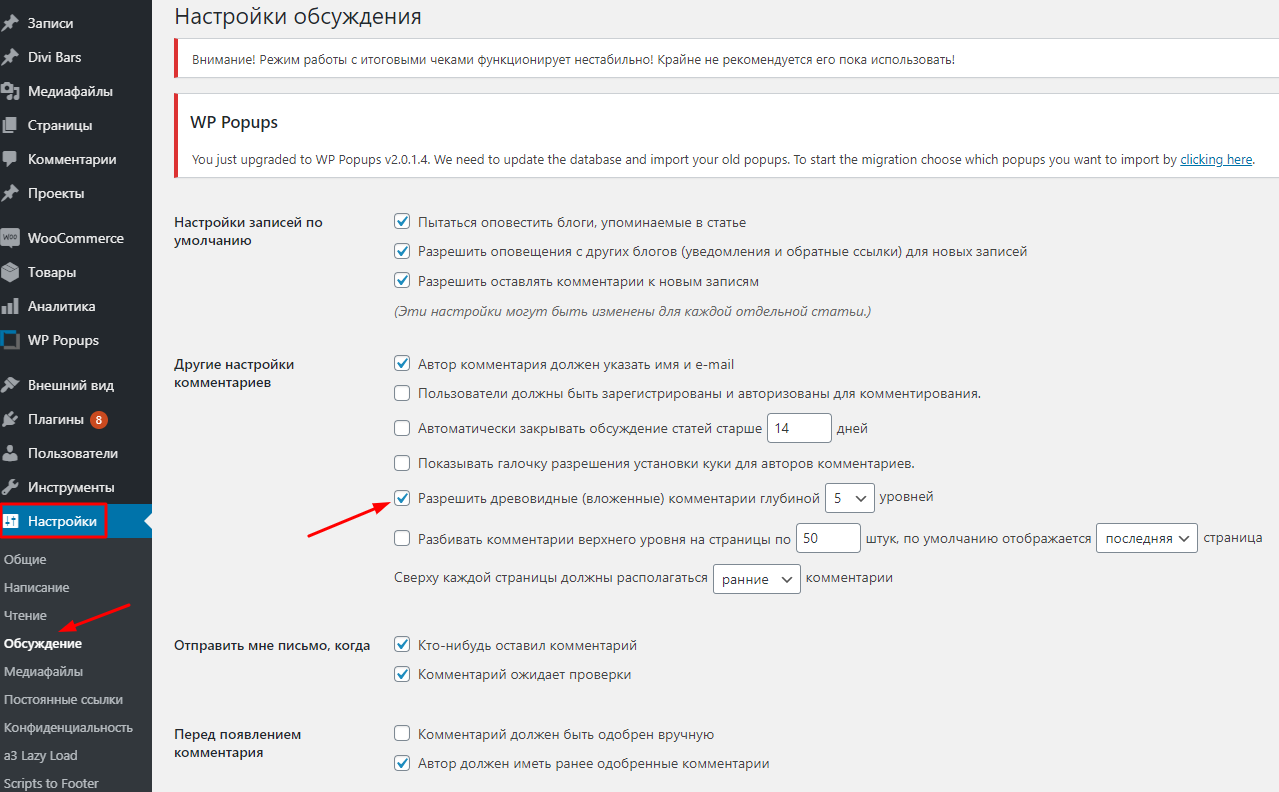
- Отключить штатный модуль WordPress для комментариев и применять Disqus либо аналогичные системы (Cackle Comments, wpDiscuz), которые устранят и проблему с дубликатами, и пользователям, в отличие от первого варианта, будет удобней.
Можно внести изменения в код относительно метода формирования адресов страниц с ответами на комментарии. Нужно закрыть URL с replytocom от индексации, применив метатег robots со значениями "noindex,nofollow". Поскольку работа подразумевает определенные знания, лучше обратиться за помощью к программисту.
Страницы пагинации
При наличии каталога с широким перечнем продукции, для удобства посетителей применяется деление на страницы, т. е. пагинация.
Чтобы скрывать документы от индексации, рекомендуется задействовать атрибут rel="canonical" тега </code>. Причем в качестве канонического адреса указывать основной URL каталога.
В качестве дополнительных мер от возникновения дубликатов страниц пагинации в поисковой выдаче можно генерировать уникальные заголовки H1, description и title по шаблону:
«H1, title либо description основной страницы пагинации – номер».

При оптимизации страниц пагинации важно учитывать несколько аспектов:
- Не добавлять уникальный контент, поскольку информация и так отличается (различная продукция). Посетителю нет смысла переходить из поисковой выдачи на 2-10 и т. д. страницы каталога. Клиенту важно начать с начала, а впоследствии посетитель самостоятельно решит, стоит двигаться дальше либо нет.
- При публикации в интернет-магазине SEO-текстов на категории товаров заранее предусмотреть, чтобы такая продукция отображалась только на первой странице. Это позволит исключить дублирование контента.
Как выявить дубли страниц
Для выявления дубликатов страниц можно применять различные способы.
Ручной поиск
При знании особенностей CMS, на которой работает ресурс, можно найти дубли страниц в поисковой выдаче, для чего достаточно ввести в строке запрос:
site:{название домена} inurl:{часть URL}
Например, если на сайте формирование адресов страниц пагинации происходит посредством GET-запроса ?page=, в строке поиска Google прописывается необходимый запрос, в результате чего обнаруживаются 4 копии:
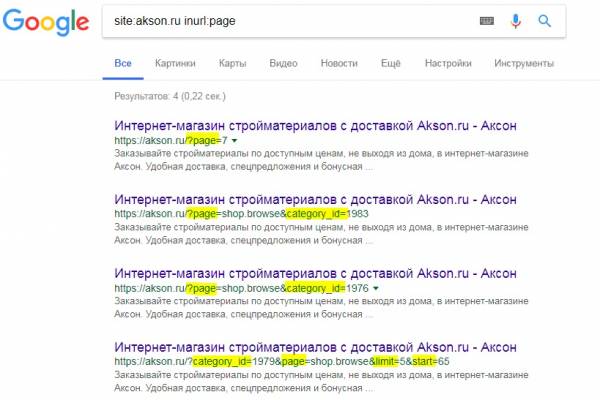
Из выдачи понятно, что в дублях страниц присутствуют и запросы ?category_id=, ?start=, ?limit=. По ним также нужно проверить площадку на копии.
Аналогичный прием действует и в Яндексе. Итог – 18 дубликатов страниц:
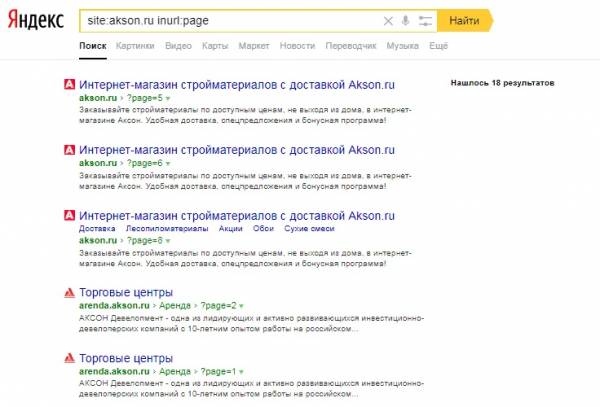
Несмотря на эффективность метода, ручной поиск копий желательно использовать только для экспресс-анализа. Для систематической работы и удобства лучше применять другие приемы.
«Яндекс.Вебмастер»
Сообщения о копиях страниц, которые найдены на площадке роботами Яндекса, можно просмотреть в разделе «Диагностика».
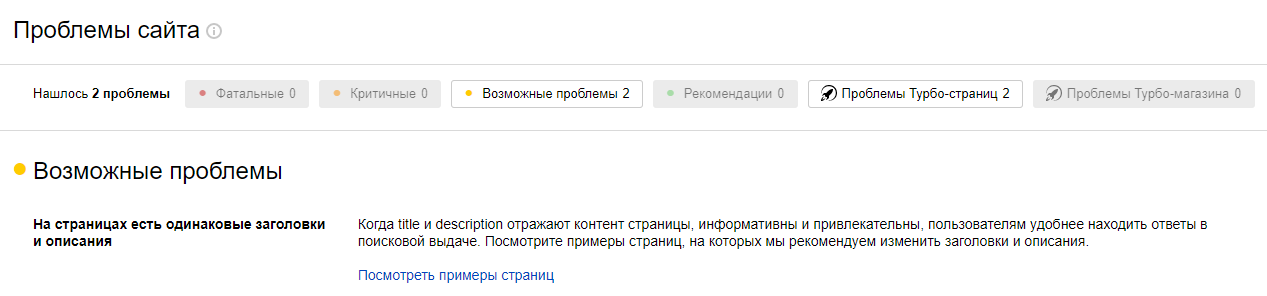
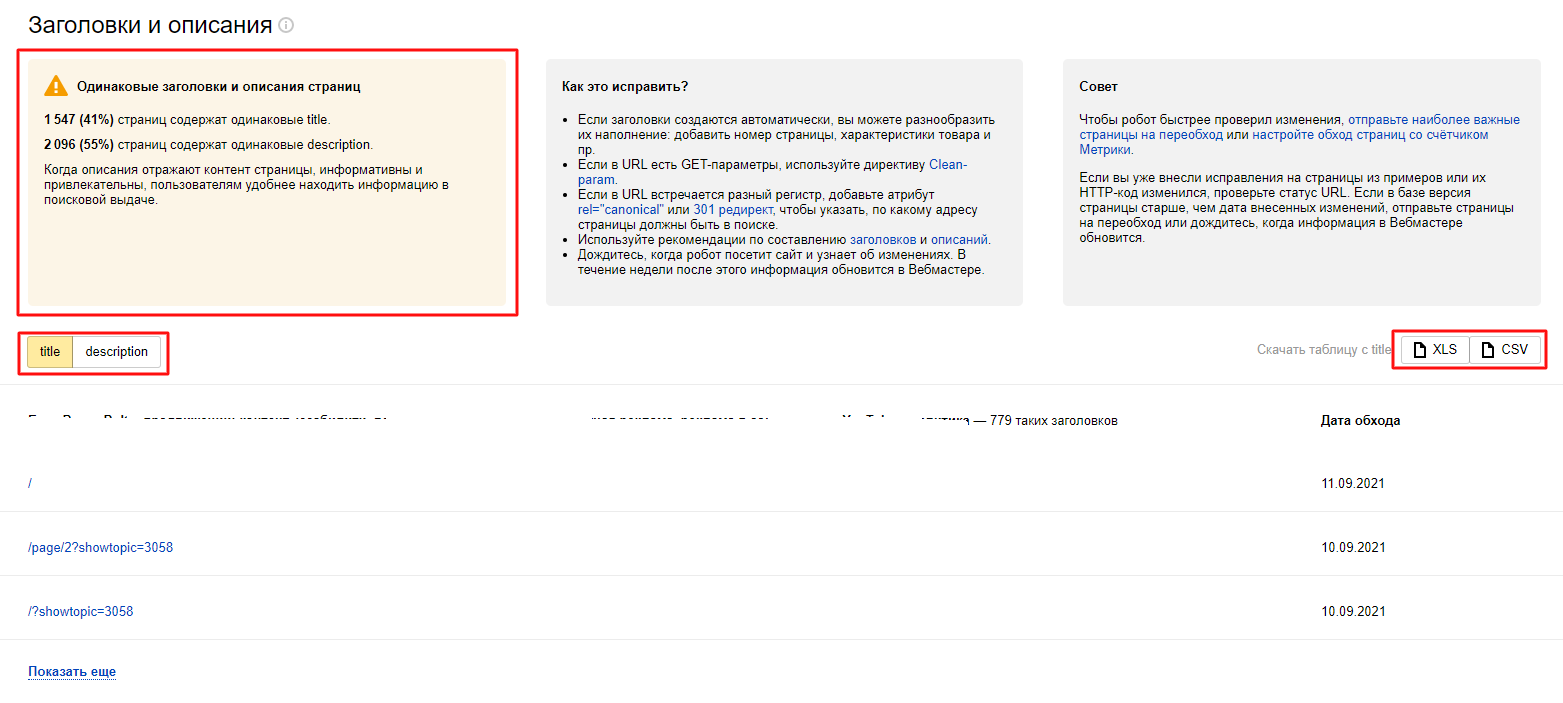
Примеры адресов с аналогичными тегами title и description присутствуют в пункте «Индексирование»/«Заголовки и описания»:

Если имеются дубли, в разделе будут показаны сведения о числе затронутых страниц. Идентичное уведомление присутствует и в пункте «Сводка». Вебмастер может ознакомиться с рекомендациями по исправлению проблем. Для удобства работы готовая таблица с адресами выгружается в форматах CSV, XLS.
Однако можно не ожидать появления сообщений, а заранее выявить дубли, поскольку «Яндекс.Вебмастер» предоставляет такие возможности:
- Зайти в подраздел «Индексирование», после – «Страницы в поиске».
- Активировать вкладку «Все страницы» и выгрузить отчет в формате XLS.
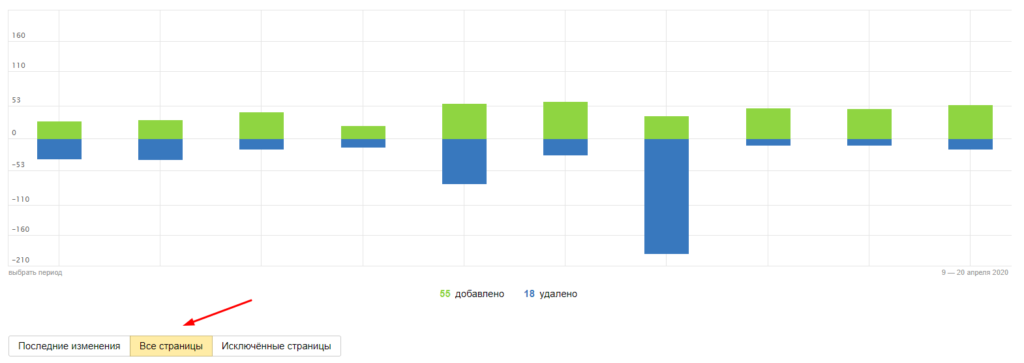
- Просмотреть список адресов и отыскать дубликаты. Для удобства рекомендуется использовать фильтрацию по фрагментам URL.
Также можно ознакомиться с количеством «Исключенных страниц».
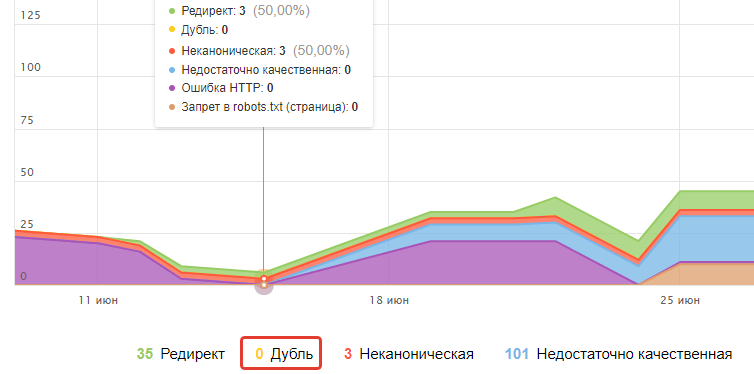
Адреса убираются из индекса по различным ным причинам, которые указываются под ссылкой, в т. ч. из-за копий контента.
Специальные программы
Дубли страниц на сайте можно отыскать посредством различных программ, которые бывают как платными, так и условно-бесплатными (с пробной версией либо ограниченным функционалом), а также без взимания оплаты.
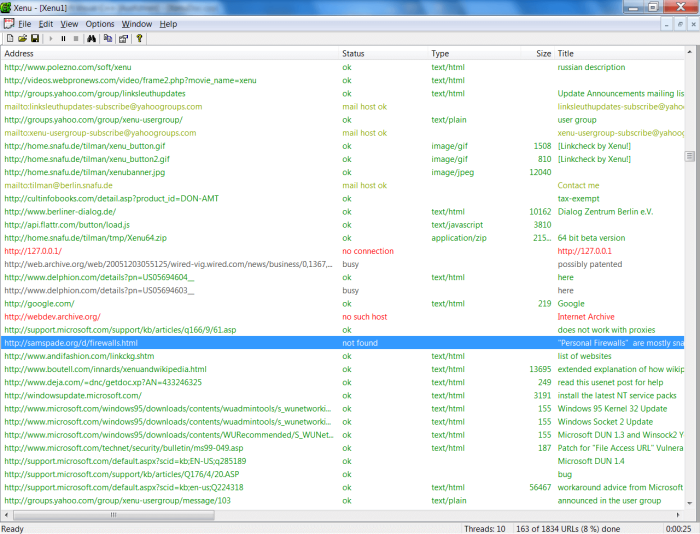
Xenu
Xenu – бесплатная программа, позволяющая анализировать даже не проиндексированные площадки. После сканирования сайта отобразятся повторяющиеся заголовки, мета-описания.
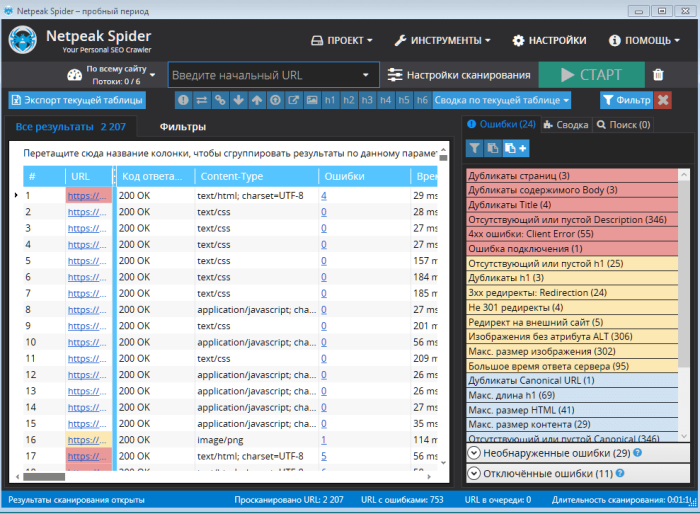
NetPeak Spider
>NetPeak Spider считается платной программой, однако для ознакомления с функционалом предоставляется пробная версия на 2 недели. Если выполнить поиск по определенному сайту, появится список всех найденных дублей и возможных ошибок.
Screaming Frog Seo Spider
Screaming Frog Seo Spider относится к условно-бесплатным программам. Дает возможность проверить до 500 адресов, после чего нужно приобретать ключ для дальнейшего использования. Поиск дублей выполняется аналогично Xenu, однако эффективнее.
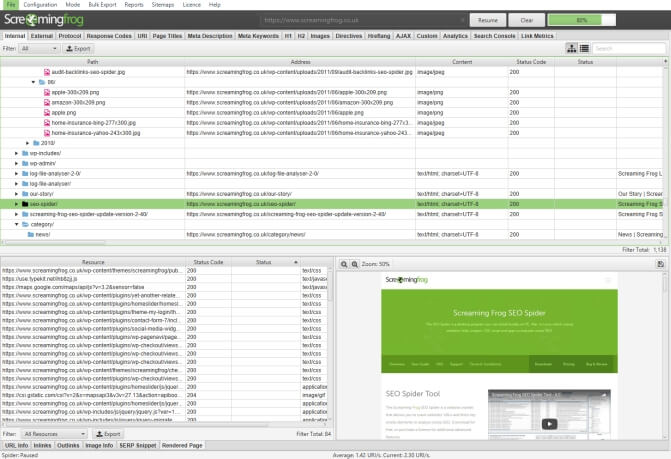
Сервисы
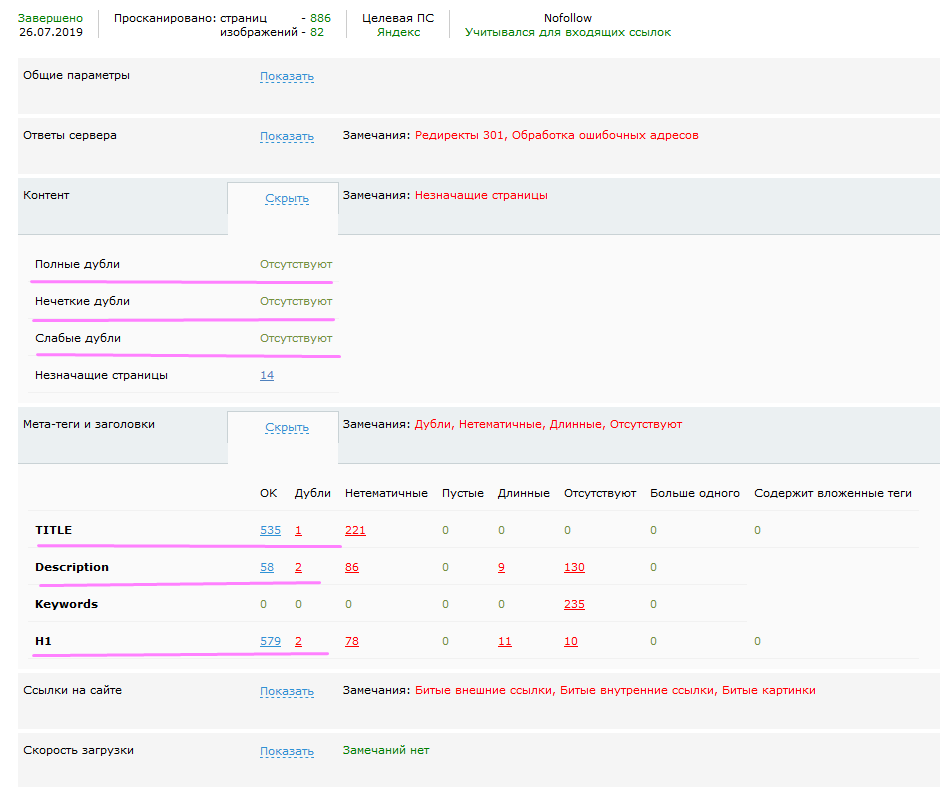
При нежелании устанавливать и осваивать программы, для поиска дублей рекомендуется воспользоваться Wizard.Sape. Анализ выполняется в автоматическом режиме, показывая результаты по истечении нескольких часов. После оплаты тарифа повторная проверка на наличие копий возможна бесплатно в течение месяца.
Помимо дублей, сервис выдает и другие сведения, включая 301-ые редиректы, страницы без контента, недействительные внешние и внутренние ссылки, изображения и пр.
Часто, при отслеживании показателей в панели Вебмастера, сопоставить данные с Google проблематично. Приходится проверять вручную, проиндексирован ли дубликат. Упростить работу позволяет парсер проиндексированных страниц от PromoPult.
Алгоритм:
- Выгрузить перечень проиндексированных адресов из Вебмастера.
- Загрузить список либо файл XLSX в соответствующее поле инструмента.
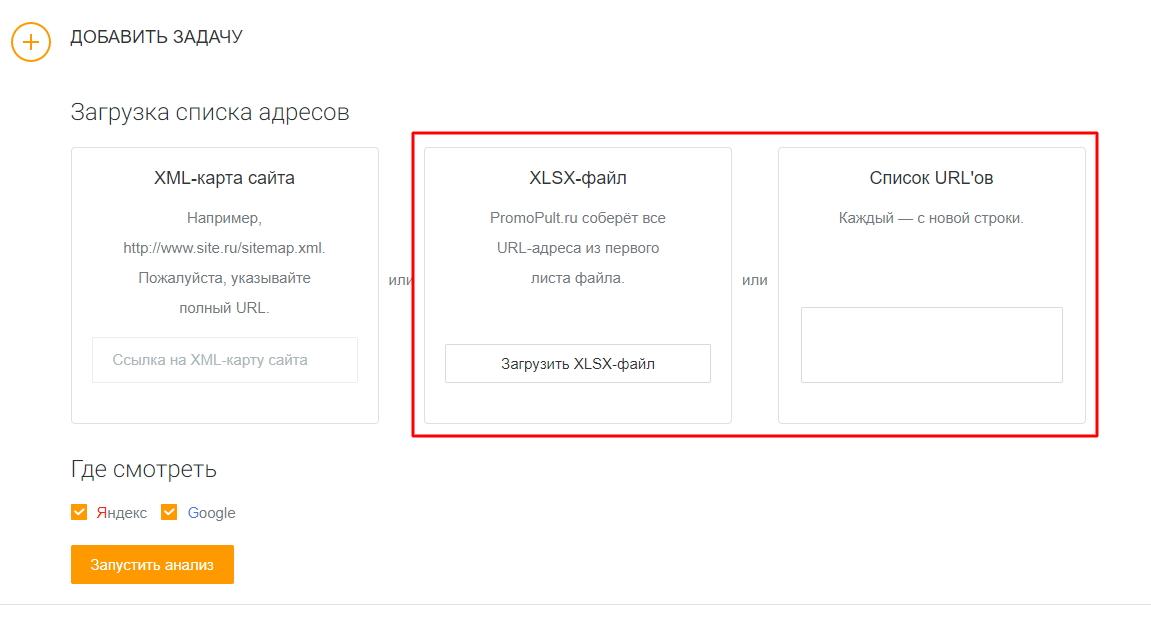
- Запустить проверку и скачать результат.

На примере видно, что страницы пагинации проиндексированы и поисковой системой Яндекса, и Гугла. Решение – настроить канонизацию для адресов и, по возможности, уникализировать описания.
Дубли отрицательно сказываются на ранжировании сайта и приводят к снижению позиций в поисковой выдаче. Копии не только уменьшают общий процент уникальности контента по отношению к основной странице, но и увеличивают время на обход ресурса роботами. Поэтому важно своевременно выявлять и избавляться от дублей.
