Основой успешного продвижения сайта в поисковых системах, или запуска контекстной рекламы, всегда являлось правильно собранное семантическое ядро. В данной статье показан весь процесс сбора и группировки запросов.
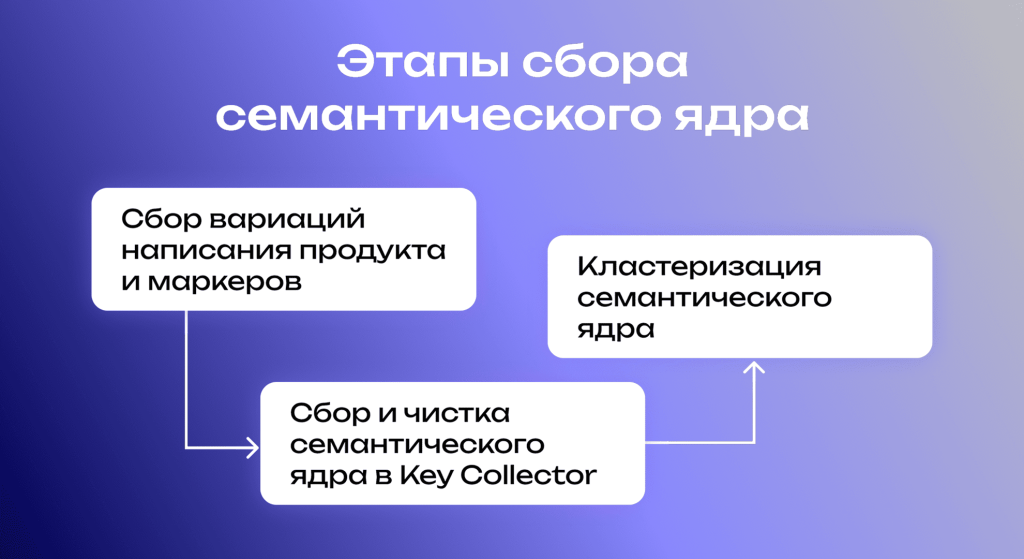
Мы разделили работу на три основных этапа:
- Сбор вариаций написания продукта и маркеров
- Сбор и чистка семантического ядра в Key Collector
- Кластеризация (группировка) семантического ядра
Каждый этап мы разберем на примере группы товаров «Шлемы для мотоцикла», для которых и соберем семантическое ядро.
Чтение статьи займет у вас чуть больше 10 минут. Но если вы не очень любите читать, то можете потратить примерно то же время на просмотр ролика.
Этап 1: Сбор вариаций написания продукта и маркеров
Перед сбором запросов, необходимо выявить все возможные варианты написания продвигаемого продукта, а также маркеры (свойства). Для этого мы используем сервис подбора слов Яндекс: https://wordstat.yandex.ru/.
Методика:
- Вписываем название нашего продукта в поисковую строку и нажимаем кнопку «Подобрать».

- Детально просматриваем запросы из правой колонки полученных результатов и выявляем синонимы или иные варианты нашего запроса.


- Переносим все найденные варианты названия продукта в отдельный файл.

- На следующем шаге следует собрать маркеры, то есть свойства, определяющие продукт. Данные маркеры можно объединить по типам схожих свойств, например, Цвет, Бренд, Тип и иных.
- Сбор и последующая чистка всей семантики по названию продукта, например, «Мотошлем».
- Плюс: Сбор всех существующих в спросе маркеров;
- Минус: Долгий и трудозатратный процесс.
- Поиск и анализ страниц конкурентов в ТОП10, которые уже имеют страницы с нашим продуктом.
- Плюс: Быстрый процесс;
- Минус: Не полный сбор свойств, если они отсутствуют у конкурентов.
- Используя второй вариант, находим сайты конкурентов по запросам названия продукта, взяв страницы из ТОП10. Это возможно сделать вводом основного запроса прямо в поисковую систему, или же воспользоваться инструментом полноценного поиска конкурентов, по видимости их сайтов, как было рассказано в 4 пункте, первого этапа, данной статьи:
- На странице конкурента, нужно обратить внимание на структуру категории, то есть, существуют ли подкатегории, или посмотреть функционал фильтрации товаров. В нем уже присутствуют группы свойств, внутри которых мы можем увидеть маркеры.

- Копируем подкатегории и/или маркеры, которые нас интересуют, то есть то, что действительно есть у продвигаемого сайта в ассортименте, и выносим в наш файл:

- Следующим шагом сцепляем все варианты написания нашего продукта с маркерами, чтобы получить различные запросы, для последующего сбора семантического ядра уже по ним. Рекомендуем использовать функцию «СЦЕПИТЬ» в программе «Microsoft Excel». В результате получим таблицу, аналогичную представленной ниже:

- Для пакетной (разовой) загрузки всех ключевых слов в программу KeyCollector следует опять воспользоваться функцией «СЦЕПИТЬ» (формируем запросы в формате «Группа:Ключ»). Таким образом, мы сможем разом добавить все запросы в единое поле программы, которая в свою очередь, создаст необходимые группы и добавит в них соответствующие запросы для расширения ядра. Итоговый список запросов в необходимом формате:

Этап 2: Сбор и чистка семантического ядра в Key Collector
Перед началом сбора семантического ядра, необходимо указать регион, по которому следует собирать запросы и их частотность. Регион напрямую связан с магазином, для которого собирается семантика, то есть если Ваш магазин находится в Москве, то и запросы с их частотностью, нужно собирать по данному региону. Для этого, в нижней части окна, мы выбираем регион для сервисов: «Yandex.Wordstat» и «Яндекс Директ»:

После выбора региона можно приступать к сбору семантики.
Методика:
- В основном меню нажимаем кнопку «Пакетный сбор слов из левой колонки Yandex.Wordstat»:

- В открывшимся окне мы увидим поле, куда необходимо добавить запросы прямо из нашего файла. После их добавления в нижней правой части окна следует нажать на иконку разделения фраз по группам:

- После нажатия на кнопку в правой колонке групп, мы увидим, что наши группы добавлены, и во всплывающем окне появилось поле с названиями наших групп, внутри которых находятся соответствующие запросы. Далее мы можем нажимать кнопку «Начать сбор»:

Запустив парсинг левой колонки «Yandex.Wordstat» мы автоматически получаем все расширения наших запросов из сервиса, и теперь не будем собирать их вручную.
- Следующим шагом является сбор корректной частоты запросов. Для этого следует очистить данные общей частотности, собранной вместе с запросами из сервиса «Yandex.Wordstat», нажав на заголовок столбца правой кнопкой мыши и выбрав пункт «Очистить данные в колонке»:

Для сбора частотности мы используем функционал «Сбор статистики Yandex.Direct»:

- Во всплывающем окне выбираем период сбора равный году. Это необходимо потому, что спрос на товары зачастую является сезонным, и без годовой частотности мы не сможем выявить самые популярные запросы. Целью сбора выбираем «Базовую» и «Уточнённую» частотность, после чего нажимаем кнопку «Получить данные»:

- Когда частотность собралась, можно переходить к чистке семантики от мусорных фраз. Мы рекомендуем удалять запросы с «Уточнённой» частотностью менее 10, так как это означает, что подобные запросы приносят меньше 1 посетителя в месяц.
Выделяем такие запросы и нажимаем кнопку «Удалить фразы»:

- Теперь можно приступить к чистке запросов по фразам.
Для этого есть несколько инструментов:
- Инструмент фильтрации – позволяет быстро отсечь часть ненужных запросов. Используя его, можно оставить в основной таблице только те фразы, которые включают в себя английские символы, цифры или состоят из 4 и более слов и т.п. для пакетного удаления.
- Инструмент «Стоп-слова» - позволяет отмечать фразы на удаление или последующий перенос в другую/новую группу, по заранее загруженным в поле словам. Можно сразу выделить запросы с вхождениями городов (отличных от выбранного региона), названий компаний конкурентов, а также информационные запросы со словами «как», «почему», «отзывы», «реферат» и пр.
- Инструмент «Анализ групп» - позволяет собрать запросы в группы по различным вариантам группировки и отмечать названия групп, выделяя сразу несколько запросов для удаления или последующего переноса в другую/новую группу.
- Рекомендуем пользоваться всеми инструментами, основным из которых должен стать «Анализ групп». Данный инструмент находиться во вкладке «Данные»:

Во всплывающим окне, можно увидеть, несколько вариантов группировки, из которых мы советуем использовать метод «по отдельным словам».
В данном методе все запросы будут присутствовать в таблице, и не случиться того, что запрос, не попавший ни в одну группу, будет исключен из таблицы и его придётся искать позже, вручную, в общем списке запросов.

- Просматривая группы одну за другой, отмечаем их, или фразы внутри них, которые явно нам не подходят. В процессе, мы будем наблюдать, что, выбирая пять групп, мы уже отметили в общей таблице 9 фраз:

- После того, как мы отметим все группы и запросы в них, мы можем закрыть данное окно и нажать на кнопку «Удалить фразы».
После чего, следует перейти к выгрузке запросов в excel для последующей ручной чистки запросов и группировки семантики.
- Чтобы совершить пакетную выгрузку всех запросов из разных групп, необходимо в правой колонке программы отметить все наши группы и нажать кнопку «Режим просмотра мульти-группы». После этого можно выгрузить наше семантическое ядро в Microsoft Excel:

Этап 3: Кластеризация (группировка) семантического ядра
Полученный список запросов, нам нужно разбить на кластеры, для последующей проработки посадочных страниц. Чтобы корректно выполнить эту задачу, нужно использовать сервисы кластеризации запросов, работающие на основе выдачи поисковых систем. Именно такой формат анализа, возможности продвижения тех или иных запросов на одной или разных страницах, дает 70% успеха при дальнейшем продвижении сайта.
Популярные программные продукты:
- KeyAssort – Программа для кластеризации и структуризации семантического ядра.
- Key Collector – Функционал «Анализ групп» с типом группировки «По поисковой выдаче»).
Популярные онлайн сервисы:
- Engine Seointellect – http://engine.seointellect.ru/login
- Tools PixelPlus – https://tools.pixelplus.ru/
- Rush Analytics – https://www.rush-analytics.ru/
Рассмотрим методику группировки запросов с помощью сервиса Engine Seointellect.
Методика:
- Полученный список запросов, который мы выгрузили из программы Key Collector, содержит столбец с названием «Группа». Нам необходимо по очереди добавлять все запросы из каждой группы в кластеризатор.

- Заходим в сервис и выбираем, в меню слева, пункт «Кластеризация запросов». В открывшимся блоке мы видим кнопку «Новая группировка».

- Нажимаем на данную кнопку. На экране появятся следующие поля для заполнения:
- Добавить запросы – в данный блок мы добавляем все запросы из первой анализируемой группы.
- Вид группировки – включает в себя три вида жесткости кластеризации:
- «Hard» - жесткая группировка
- «Balance» - группировка средней жесткости
- «Soft» - группировка низкой жесткости
Подробнее про различие работы методов группировки можно посмотреть в данном видео:
При группировке коммерческих запросов, как в нашем случае, следует изначально выбирать метод группировки «Hard», если запросы информационные, то рекомендуем пользоваться только методом «Soft».
- Регион – выбираем соответствующий регион продвижения.
- Мой сайт – не нужно указывать, так как эта функция нужна для определения запросов по уже существующим посадочным страницам указанного сайта.

- Нажав «Запустить группировку», необходимо дождаться окончания процесса сбора данных. При завершении анализа, в правой части созданного задания, вместо отображения процесса, появиться иконка «Глаз», на которую необходимо нажать.
- Мы попадаем на страницу результата группировки, и можем проанализировать данные:

- Мы видим, что все наши запросы, кроме одного, попали в одну группу (отмечено зеленым), а значит их можно продвигать вместе на одной посадочной странице.
- Также присутствует нераспределенный запрос (отмечено синим), это значит, что по данному запросу результаты выдачи сильно отличаются от результатов других запросов. В таком случае, следует сделать вывод, что под этот запрос нужно создавать отдельную посадочную страницу бренда «Ataki».
- Справа от группы есть функционал «Показать список URL», нажав на который, откроется блок со ссылками, на страницы из ТОП10, по которым была проведена кластеризация.
- Если бы мы добавили большее количество запросов в кластеризатор, то в нераспределенных могли оказаться фразы, которые можно продвигать в готовых группах. Можно просто увидеть эти запросы и перенести в нужную группу, но если фраз много, то их следует отправить на группировку по методу «Soft». Полученные группы по методу группировки «Soft» соединить с группами, полученными ранее по методу «Hard».
- Проведя данные действия с каждой группой из нашего файла, мы получим готовый список разделенных запросов, для последующей проработки страниц.
Финальная версия файла семантического ядра
Итоговый файл, с семантическим ядром, должен представлять собой таблицу, включающую следующие столбцы с данными:
- Запрос
- Группа
- Базовая частотность
- Уточненная частотность
- Посадочная страница
Все группы мы рекомендуем отделять чертой друг от друга, чтобы впоследствии, с таким файлом было легче работать:

Выводы:
Теперь Вы знаете на сколько трудозатратным является процесс сбора и группировки семантического ядра, для продвижения сайта или настройки контекстной рекламы.
Это лишь базовая инструкция, которая не охватывает многих нюансов, возникающих в процессе, но именно эта работа является основой успешного достижения целей продвижения, а значит выполнять ее некачественно равносильно бездействию, так как вы не добьетесь никаких результатов без «построенного фундамента».