Robots.txt – это текстовый документ, который оказывает значительное влияние на индексирование и продвижение любого сайта. Посредством файла владелец ресурса указывает поисковым роботам, какие разделы площадки необходимо (либо нет) учитывать при обходе.
Что такое robots.txt
Robots.txt включает инструкции и директивы для ПС, которые запрещают индексировать конкретные страницы, папки, документы и другую информацию проекта, ограничивая доступ к содержимому.
Файл в формате txt считается стандартом исключений для роботов, принятым консорциумом W3C в 1994 г. Задействуется большинством современных поисковиков в качестве рекомендации при индексировании ресурса. Если у сайта отсутствует robots.txt, ПС воспринимают страницы (независимо от их назначения) открытыми.
Зачем нужен
Контентные площадки либо медиа проекты могут обходиться без указаний ПС, поскольку в индексации принимают участии все страницы. Однако на других сайтах часто находятся разделы, которые показывать роботам не нужно. Например:
- админ-панель, т. е. адреса, начинающиеся с /user, /admin;
- пустые разделы (при отсутствии контента они не помогут в индексации);
- регистрационные формы;
- поиск по сайту
- личные страницы пользователей в интернет-магазинах (кабинеты, корзины и т.п.).
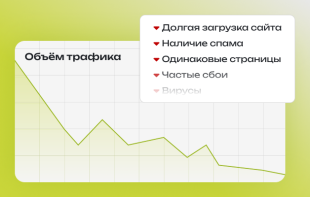
Robots.txt выполняет важную функцию в поисковой оптимизации сайта. Роботы при каждом сканировании площадки обращаются изначально именно к указанному файлу, чтобы узнать, можно ли индексировать страницы. Ненужные разделы, которые не содержат никакой полезной информации для целевой аудитории, исключаются из поиска, прописывается путь к Sitemap.
Корректная настройка файла влияет на видимость сайта в выдаче ПС и последующий трафик площадки. При допущении ошибок в инструкциях и директивах ресурс может полностью исчезнуть из поискового индекса. Поэтому SEO-специалисты, при изучении проекта, который нужно продвигать, уделяют первостепенное значение проверке текстового документа robots.txt.
Где находится
Robots.txt находится в корневой директории. Например, на https://site.ru путь к файлу следующий: https://site.ru/robots.txt.
Как создать
Чтобы создать файл, можно воспользоваться текстовыми редакторами (блокнот, TextEdit и др.). Не рекомендуется применять приложения Microsoft Office, поскольку данные часто сохраняются в неподходящем формате либо произвольно добавляются ненужные символы, нераспознаваемые поисковыми системами. Готовый robots.txt помещается в корневой каталог, т. е. папку с названием сайта.
Для загрузки файла на сервер можно использовать:
- консоль, админку в CMS;
- панель управления (например, Cpanel, ISPmanager);
- FTP-клиент (FileZilla, TotalCommander).
Для получения файла можно воспользоваться и такими онлайн-генераторами, как IKSWEB, Smallseotools, PR-CY.

Но метод, несмотря на автоматическую генерацию, может потребовать от владельца сайта самостоятельной корректировки файла. Поэтому нужно знать базовые знания синтаксиса и правила составления текстового документа.
Также в Интернете можно отыскать готовые шаблоны robots.txt для популярных платформ (например, WordPress, Drupal, Joomla). Это исключает многократное написание стандартных директив, причем в документе учитываются нюансы определенного движка. Однако и здесь важны минимальные познания, поскольку шаблон не предоставляет корректно настроенный файл, а каждый проект – индивидуален.
Можно создать robots.txt посредством плагинов. В результате файл установится самостоятельно. Если владелец ресурса использует CMS хостинга, редактировать текстовый документ не понадобится, к тому же у пользователя иногда и вовсе отсутствует такая возможность, т. е. провайдер автоматически указывает поисковым алгоритмам, нужно ли сканировать информацию, при помощи специально созданной страницы с настройками либо другого инструмента.
Выбор cms - https://www.unisender.com/ru/blog/idei/cms/
Как настроить
После создания файл можно настраивать в ходе оптимизации сайта непосредственно в самом текстовом документе с соблюдением правил и синтаксиса. По завершении редактирования потребуется выгрузить обновленную версию robots.txt. Для CMS процесс упрощается за счет специальных дополнений и плагинов, позволяющих вносить изменения напрямую с админ- панели.
При настройке файла важным считается соблюдение синтаксических правил и следование определенным рекомендациям и характеристикам, что влияет на корректность работы документа. Например:
- Название файла – robots.txt. Заглавные буквы, кириллица и различные символы не допускаются.
- 1 сайт – 1 файл. Использовать 2 и более текстовых документов для единственного ресурса нельзя.
- Место размещения robots.txt – корневая папка. Например, чтобы контролировать сканирование всех страниц http://сайт.ru/, файл должен находиться по адресу: http://сайт.ru/robots.txt. Размещать документ в подкаталоге (http://сайт.ru/pages/robots.txt) запрещено. В случае невозможности получения доступа к корневой папке нужно связаться с провайдером. Важно учитывать, что размещать файл допускается по URL с субдоменами, нестандартными портами (http://website.сайт.ru/robots.txt, http://сайт.ru:8181/robots.txt).
- Трактовка любого текста, который находится после символа #, означает «комментарий». Это позволяет оптимизаторам оставлять пометки к инструкциям, напоминающие причину, повлиявшую на закрытие файла от индексации, открытие доступа к определенным разделам, страницам.
- Создание файла – в формате текстового документа в кодировке UTF-8, которая включает коды символов ASCII.
- Названия правил – с заглавной буквы на латинице. Например, конкретное написание – Allow, а не ALLOW.
- Отсутствие закрывающих символов в директивах. В конце правил запрещено проставлять точку и др.
Файл robots.txt содержит группы, в которых разрешено прописывать несколько директив с отдельной строки. Каждая их них включает информацию, для какого User-agent пишется указание, к каким каталогам предоставлен доступ и т. п. Инструкции в группах считываются сверху вниз.
Поисковым роботам не принципиальна последовательность директив. Например, если Allow и Disallow противоречат друг другу, в приоритете окажется первая.
В файле не рекомендуется прописывать инструкции для каждой страницы. Хотя это не считается запретом, лучше указать общие директивы, которые применимы для всех типовых URL проекта.
Директивы для robots.txt
В robots.txt указываются различные директивы для поисковых алгоритмов, которые помогают понять роботам, какие разделы и страницы индексировать либо нет. Каждая из них отвечает за выполнение определенных функций.
User-Agent
Считается обязательной директивой, которая указывается в начале файла. Определяет, к какому из поисковых алгоритмов относятся прописанные правила.
Основные типы роботов, которых можно перечислить в User-agent:
- Google (все боты Google);
- Googlebot (главный бот Google);
- Googlebot-Image (индексирует изображения);
- Yandex (все боты Yandex);
- YandexBot (главный бот Yandex);
- YandexImages (индексирует картинки);
- YandexMedia (индексирует видео и прочий мультимедийный контент).
Если перечень директив прописывается для всех возможных поисковых алгоритмов, ставится «*». Например, User-agent: Yandex означает, что правило применимо к боту Yandex, а user-agent: * – ко всем ботам.
Disallow
Самая распространенная директива, которая запрещает индексацию конкретных страниц (служебных, технических, пагинации, с личными пользовательскими данными, результатами поиска внутри ресурса, дублей) либо разделов сайта. Disallow допускает употребление специальных символов «*» и «$».
Директива запрета индексации разрешает указывать как каталог, так и часть названия, полный путь документа. Например:
- Для полного запрета индексации документа путь определяется от корневой папки проекта (выделено красным на рисунке).
- При запрете индексации документов 2 и выше уровней указывается полный путь либо впереди адреса проставляется знак «*» (синяя стрелка на изображении).
- При запрете индексации каталога запрещенными становятся все страницы, которые относятся к разделу (зеленая стрелка на рисунке).
Также можно запретить для индексирования документы, в адресах которых имеются конкретные символы (показано розовой стрелкой).
Allow
Директива, в отличие от Disallow, наоборот, разрешает поисковым ботам обход указанных страниц либо разделов веб-площадки. Устанавливается по умолчанию для всех документов на сайте, если не прописаны другие требования. Директива Allow, как и Disallow, допускает применение специальных символов и может:
- Разрешать для индексации документы, адреса которых содержат конкретные символы.
- Открывать к индексации документы (показано на рисунке синими стрелками), которые по определенной причине расположены в каталогах, закрытых от роботов (отображено красными стрелками).
Нужно учитывать правила использования директив, т. е. Allow и Disallow из соответствующей группы сортируются по длине префикса URL и задействуются последовательно.
Allow
Директива сообщает роботам, где находится XML-карта сайта. Рекомендуется указывать полный путь URL. При наличии на ресурсе нескольких карт допускается прописать столько же адресов. Например:
User-agent: *
Sitemap: https://сайт.ru/sitemap-1.xml
Sitemap: https://сайт.ru/sitemap-2.xml
Специальные символы, которые прописываются в директиве, означают следующее:
- «*» – любая последовательность символов (добавляется по умолчанию в окончании каждой директивы);
- «$» – отменяет знак «*» на конце правил;
- «#» – используется для комментариев, т. е. информация, указанная после знака, не станет учитываться поисковыми ботами.
Clean-param
Директива запрещает роботам обход адресов с динамическими параметрами, полностью дублирующих контент основных страниц. Такая ситуация больше характерна для сайтов интернет-магазинов, т. е. относится к URL, предназначенным для персональных идентификаторов пользователей, передачи данных по источникам сессий. Clean-param применяется для удаления параметров из адресов площадки. Часто может использоваться, чтобы убирать метки отслеживания, фильтры и т. п.
Директива относится к Yandex, поскольку для правильной обработки информации ботами Google разработана функция «Параметры URL» в Search Console.
Crawl-delay
Инструкция ограничивает частоту посещений роботами, т. е. задает в секундах минимальный временной интервал между окончанием загрузки одного документа и началом последующего. За счет директивы понижается нагрузка на сервер, что особенно актуально для крупных порталов с большим количеством разделов и страниц.
Crawl-delay учитывается только ботами Yandex (хотя сейчас директива не поддерживается), в Google применяется функция «Настройки сайта» (находится в Search Console).
Host
Директива предназначается для указания основному роботу Yandex главного зеркала ресурса, если присутствует доступ к площадке по нескольким доменам. Однако с 2018 г. инструкция не поддерживается, поскольку аналогичные функции выполняет раздел «Переезд сайта» в Вебмастере» и 301-ый редирект.
Для корректного отображения главного зеркала в Google задействуется инструмент «Настройки сайта», доступ к которому можно получить в Search Console.
Что исключать из индекса
Из индекса рекомендуется исключить страницы и разделы:
- с неуникальным контентом, причем документы желательно скрывать от роботов, прежде чем информация попадет в индекс;
- не несущие никакой смысловой нагрузки для пользователей (без содержания, результаты поиска, несуществующие);
- используемые при однотипной работе сценариев (например, с такими сообщениями, как «Спасибо за отзыв!» и т. п.).
Также поисковым ботам нужно запретить включать в индекс любые дубли. Доступ к разделу либо странице происходит только по единственному адресу, после чего по URL открывается уникальное содержание, не имеющее повторов. Дубли часто возникают при работе сайта на CMS при создании новых записей, из-за динамических ссылок. Для скрытия можно воспользоваться масками:
Disallow: /*?*
Disallow: /*%
Disallow: /index.php
Disallow: /*?page=
Disallow: /*&page=
Исключать из индекса нужно и страницы, которые содержат индикаторы сессий. Здесь тоже можно воспользоваться директивой Disallow:
Disallow: *PHPSESSID=
Disallow: *session_id=
Также из индекса убираются файлы движка управления ресурсом. К ним относятся документы шаблонов, тем, админ-панели, баз и др.:
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/themes
Disallow: /wp-content/cache
Disallow: /wp-content/plugins
Disallow: /trackback
Robots.txt для Яндекс и Google
Для наглядной демонстрации правильно оформленного файла с директивами под Яндекс можно привести пример robots.txt для WordPress:
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /wp-trackback
Disallow: /wp-feed
Disallow: */trackback
Disallow: */feed
Host: site.com
Директива Host указывает роботу Яндекса, какое зеркало ресурса считается основным. Причем наиболее распространенные варианты – site.com и www.site.com. Однако важно учитывать, что директива не выступает прямой командой, т. е. изначально Яндекс находит и идентифицирует сайты как зеркала, и только после правило станет работать.
Для Google настройка файла практически не отличается. В качестве примера:
User-agent: Googlebot
Allow: *.css
Allow: *.js
Disallow: /cgi-bin
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/cache
Disallow: /wp-content/themes
Disallow: /wp-trackback
Disallow: /wp-feed
Disallow: */trackback
Disallow: */feed
Разница – в отсутствии директивы Host. Дополнительно присутствуют 2 указания, которые разрешают индексацию CSS-таблиц и JS-скриптов. Это связано с рекомендацией ПС, где поясняется о необходимости разрешения роботам уделять внимание файлам темы (шаблона) площадки. Сами таблицы и скрипты в выдачу не смогут попасть, но такой подход даст возможность ботам корректнее выполнять индексацию ресурса и отображать сайт в результатах поиска.
Как проверить
Чтобы проверить robots.txt, достаточно воспользоваться сервисами Google и Яндекса. Причем последний предоставляет возможность проанализировать файл и без ресурса. Например, если документ готов, но пока не загружен. Для проверки нужно:
- Перейти в панель «Яндекс.Вебмастер».
- Вставить в появившемся окне текст robots.txt и нажать на кнопку «Проверить».

При правильном заполнении файла система не обнаружит никаких недочетов.

При наличии ошибки последняя подсветится, появится описание возможной проблемы.

Сервис «Яндекс.Вебмастер» позволяет выполнить проверку файла и по адресу сайта. Для анализа необходимо указать следующий запрос: сайт.com/robots.txt.

Также проверить robots.txt можно и посредством Google Search Console, для чего изначально нужно подтверждение прав на владение ресурсом.
Распространенные ошибки
Несмотря на относительно несложную задачу по созданию robots.txt, при заполнении файла многие допускают ошибки, к которым относятся:
- Полное закрытие площадки от индексирования. Это приводит к исключению всех разделов и страниц из выдачи ПС и снижению трафика.
User-agent: *
Disallow: /
- Неправильное зеркало. Возможно, ПС проигнорирует директиву. Но если имеется несколько субдоменов для различных регионов, может произойти «склейка» зеркал.
User-agent: *
Host: site.ru # Хотя верно – sub.site.ru
- Игнорирование меток отслеживания, т. е. не закрытие их от индекса. Подобная ошибка часто приводит к возникновению значительного количества дублей страниц, что в результате отрицательно сказывается на продвижении проекта.
Robots.txt считается необходимым инструментом взаимодействия с поисковыми алгоритмами и выполняет важную функцию в SEO, поскольку позволяет напрямую влиять на индексацию ресурса. Поэтому рекомендуется корректно заполнять файл, что позволит сайту лучше индексироваться и выше ранжироваться в результатах выдачи.